
This blog post was written by Dr Stephen Gadd, Software Developer and GIS Consultant.
The IHR’s Centre for the History of People, Place and Community has been carrying out some exploratory research on the potential of analysing London’s medieval customs accounts digitally. Detailed, or ‘particular’ customs accounts recorded immense detail about the goods and practices of trade, giving an unparalleled insight into the medieval material world and international networks. The challenge of these sources, however, is in their sheer scale, and their complexity. Dr Stephen Gadd has been undertaking proof-of-concept work, ‘upcycling’ a single year’s customs accounts into rich digital data suitable for analysis.

Medieval England’s customs officers, including Geoffrey Chaucer himself, kept amazingly detailed records of every liable consignment on every ship at every port in the land, not least London. Some 100,000 words were written up in Latin annually into the books which make up the surviving records of the taxation of London’s foreign trade up to 1560: perhaps four or five million words in total. These sources promise the potential to explore fascinatingly-detailed stories of the nation’s fluctuating prosperity, of industrial and agricultural development and decline, and of changing fashions and tastes.
In order to make sense of such a mass of information, we need to transcribe, translate, and categorise each word. Fortunately, the customs entries for each shipment followed much the same standard formula throughout the medieval period, and indeed into the Early Modern period following the introduction of “Port Books” in 1565. This consistency offers the potential to use automatic software indexing to start to make sense of this wealth of data, through the categorisation of the names of ships, their origins and destinations, their masters and merchants, and the commodities they carried.
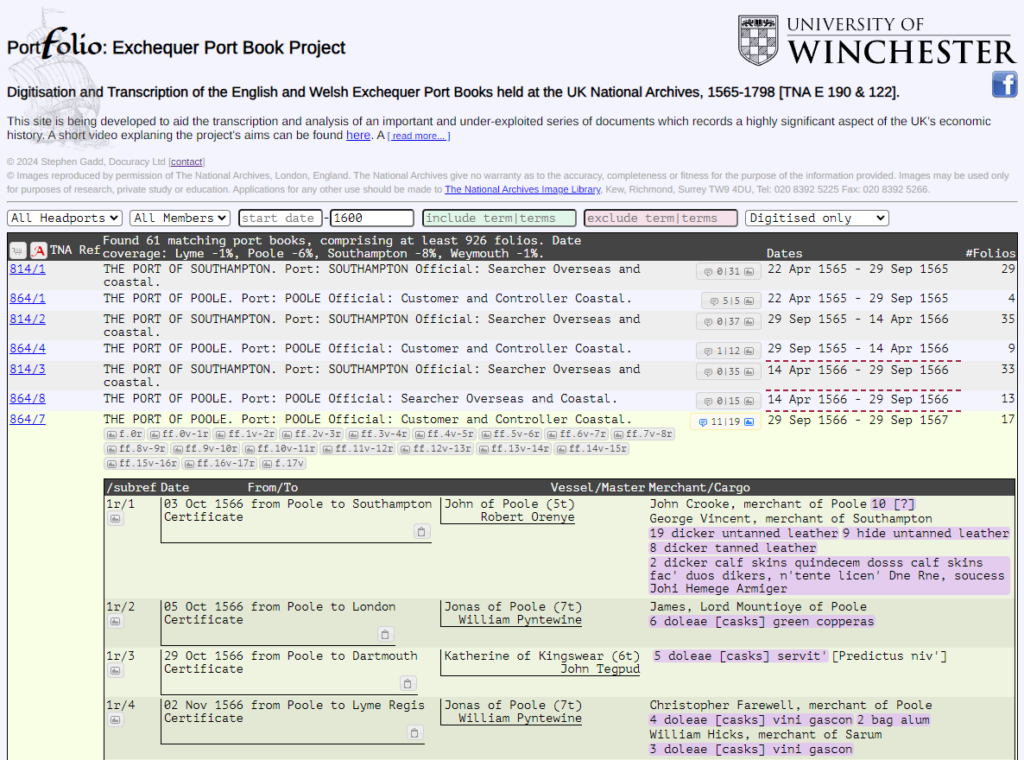
Recognising the potential for much more detailed quantification and analysis of trends, between 1986 and 1998 the The Gloucester Port Books Database, 1575-1765 was created, demonstrating the utility of a computational approach. This was the inspiration for the Portfolio: Exchequer Port Book Project which I instigated at the University of Winchester in 2012, as a pilot study for the feasibility of the online crowd-sourcing and -transcription of photographs of other Port Books. This project faltered due to the unavailability of a large proportion of the Port Books at The National Archives following the discovery of a mould infestation, but was then put on hold when it became apparent that AI technologies would soon be able to facilitate the transcription. Funded by a Cambridge Digital Humanities grant, in 2021 I trained a Handwritten Text Recognition model on the Transkribus platform using a large sample of Latin Port Books from the late sixteenth and early seventeenth centuries.

My preliminary work for the proposed Medieval London Customs Accounts project has focussed on modelling a database and populating it with data extracted from Stuart Jenks’s astonishing transcriptions. He worked painstakingly to create manually a thorough and annotated transcript of surviving entries covering the period 1280 to 1560, together with a glossary and index: my task has been to create algorithms (using Python) for assimilating these outputs, to begin the process of word-categorisation (computational tagging or “labelling”) which will enable the development of a Named Entity Recognition (NER) model. This will in turn facilitate the further enrichment of the labelling of Jenks’s transcriptions, and might also be applied to automated transcriptions of other customs accounts generated through Transkribus.


Once the individual words identifying ships, places, commodities and their quantities, and people have been labelled, it will be possible to perform automatic translations, group together synonyms and spelling-variants, and geolocate identifiable places. The resulting downloadable dataset would be complemented by a simple toolkit empowering researchers and enthusiasts alike to both make simple index queries and perform complex statistical analyses, without the need to install any software. Almost instantaneously, the toolkit would generate graphs showing dimensions such as commodity volumes and values over decades or even centuries, or the activity of ships and merchants, and maps showing the geographical flow of merchandise into and out of London and around the world.
The proof-of-concept work carried out for the year 1480-1 has demonstrated the feasibility and potential of digitally upcycling these transcribed records. This fusion of historical research, AI technology, and meticulous transcription efforts could give an unprecedented understanding of London’s medieval trade. But much more work is required to allow us to unlock the potential of examining change over an almost-continuous 180-year run of records.
