By Jonathan Blaney
In June we added to British History Online records of 22,500 History PhDs awarded in UK and Irish universities between 1970 and 2014. This set of 22,000 theses was added to BHO’s existing series of 7500 records of research degrees awarded between 1901 and 1970.
As we explained in an accompanying blog post in June, this selection isn’t every History PhD but it is the fullest record we have of research activity in UK universities in the 20th and early 21st century. With these records we can start to map new connections in terms of research topics and people active in the PhD process – as students, supervisors and examiners.
Alongside these published records, we now release the underlying data for these 30,000 theses. Here Jonathan Blaney, Editor of BHO, explains the data and its structure, and what you can do with this additional content.
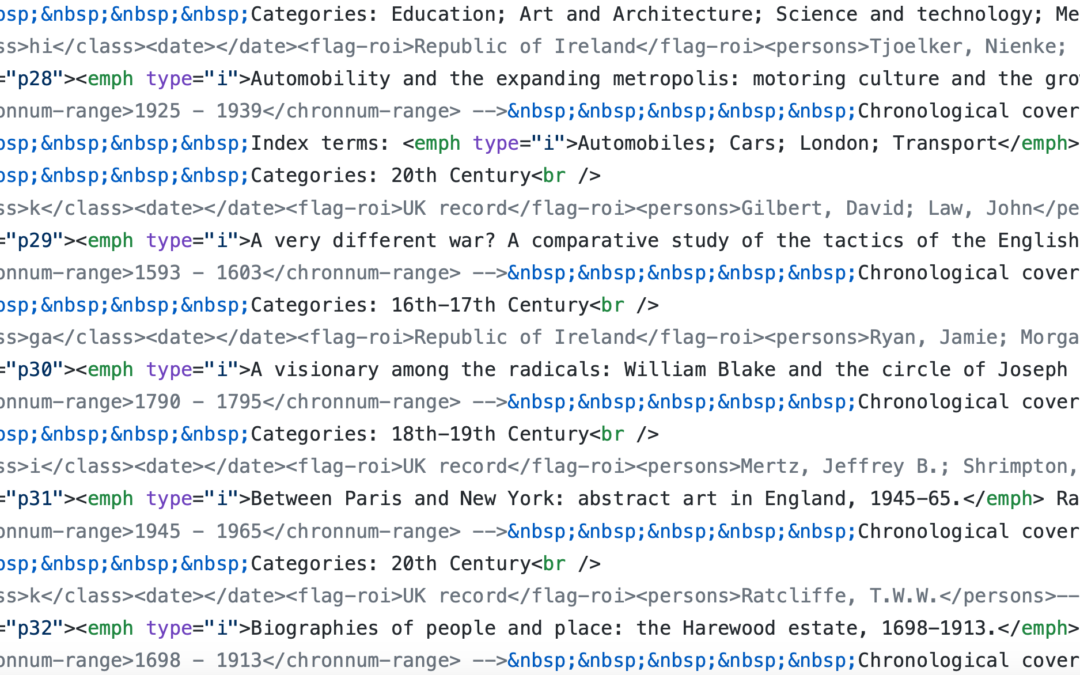
In June 2020 we made available on British History Online the IHR’s print records of History PhDs (and some Masters degrees) awarded up to the year 2014. Because of its complex provenance, you’ll find this information appearing on BHO in two sets of records: Theses, 1901-1970 (7500 items) and Theses 1970-2014 (22,500 items).
As explained in our previous blog post, these records have been digitised from annual IHR print publications and what you see on screen is what appears in the original publication –- give or take some amplification of the post-1970 records where we’ve incorporated index and category terms to improve searching. The two published sets are independently text searchable, and you can also search across all 30,000 theses, 1901-2014. The published BHO record is certainly the easiest place to search and browse these records. Again, our first blog post provides a guide on how to text search the published listings on BHO.
The files that you read on British History Online are stored in the markup language XML. For those who would like direct access to the datasets, we’ve now published them on an open Github repository (a repository is simply a collection of files) under a Creative Commons licence. This allows anyone interested to take a copy of the data to do their own work on it. The repository can be found here. If you haven’t used a repository like this before, you should know that you can download all of the data by clicking the ‘clone or download’ button on the main page. A description of how the data is organised is in the file called README.md, which is also displayed at the bottom of the main page for the repository.
If you’d like to perform complex queries on the data, of a kind which are not possible via text searching on BHO, then we recommend that you use the 1970-2014 data (the richer of the two available sets) in the folder flat-files-1970-2014. These have had additional work done on them, for example to add missing geographical region information, and are organised as one thesis per line.
The easiest way to search through the data is using a text editor, such as Notepad or TextEdit (a program like Microsoft Word will probably destroy the data). We have split the data into five files to make it more manageable. With something like Notepad you can open one of those files and search for the specific information you want by appending an XML tag before it. For example, each university appears like this:
<university>Manchester</university>
You can therefore search for Manchester University theses with:
<university>Manchester</Manchester>~
You can even do a rough count of Manchester University theses per file by doing a find-and replace for:
<university>Manchester</Manchester>
and replacing it with itself. Most text editors report how many replacements were made.
However caution is required, because names for the same institution may appear differently: the 1970-2014 data we’re using derives from historic files that contain variations in markup. Therefore Manchester appears with these forms:
<university>manchester</university>
<university>Manchester</university>
<university>Manchester </university>
<university>Manchester </university>
<university>Manchester </university>
<university>Manchester </university>
This kind of variety is common in digital resources, but by making all of the data available we make the variations visible and give researchers the opportunity to work with them.
To help users scope the varieties of name forms we have created an alphabetised list of universities as found in the theses data, list-of-universities.txt, in the same folder. The list allows users to see that there are two forms which may confound a search for <university>Manchester
<university>Manchester Metropolitan</university>
<university>Manchester (UMIST)</university>
Some researchers may simply want to exclude Manchester Metropolitan; others will want a more fine-grained approach that takes account of the merger of Manchester University and UMIST.
Similarly we have created a list of thesis supervisors: list-of-supervisors.txt. Supervisors’ names vary more than institutions’, largely because of the different forms in which personal names may be abbreviated or given in full when submitted annually by university departments as part of the original records. For example:
Foster, R.F. Foster
R.F. (Roy) Foster
Robert F. (Roy)
Foster, Roy
For those who wish to do more complex searching we recommend the free grep program, for which there is a very good introduction on the Programming Historian website.
Using grep or similar tools makes it easy to extract or count data from multiple files very quickly. For example, how many History theses with the category ‘Britain and Ireland’ were completed and awarded in 1985? A quick grep gives the answer as 254. Of those, which university accounts for the most theses? Here are the top 10 derived from a quick search:
| 44 | Oxford |
| 35 | London |
| 19 | Cambridge |
| 12 | Edinburgh |
| 10 | Keele |
| 9 | Manchester |
| 7 | Wales (Aberystwyth) |
| 7 | Liverpool |
| 7 | Lancaster |
| 7 | Council for National Academic Awards |
These results could be refined with a bit more time, but indicative results can be obtained very quickly.
As well as data files, in XML format, we have also shared a couple of fairly simple Python scripts that we used to convert the database output file into BHO syntax. This allows users to see what we did and to modify the scripts if they wish to make different choices.
By taking your own copy you can use your own preferred tools and techniques to explore this rich dataset of theses.
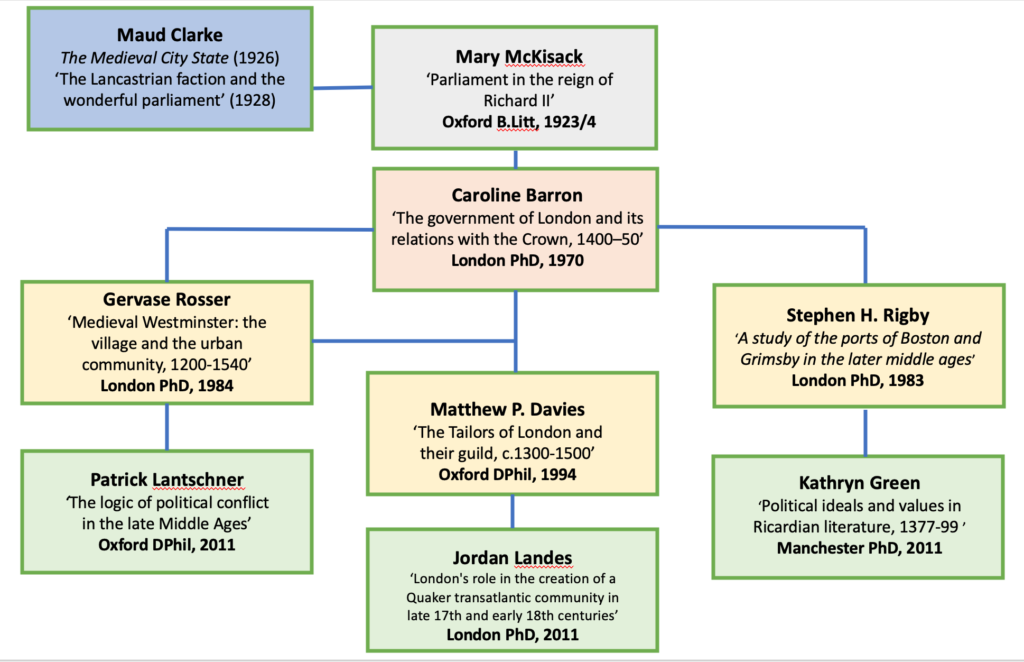
At BHO we’re interested in what this data can tell us about trends and patterns, in terms of research topics students and supervisors over time. Our initial intention is to investigate ‘family trees’ of historians, thinking of a supervisor’s supervisor as a kind of intellectual ancestor of a particular doctoral candidate. In the previous post we recreated just one such ‘tree’ but now hope to create bigger networks in which the known gaps in the data will not impair general impressions of broader trends and connections.
If you use the data, in straightforward or complex ways, please let us know what you did with it!
About British History Online

British History Online (BHO) is the IHR’s digital library of nearly 1300 volumes of primary and secondary content, with a focus on British and Irish history, c.1200-1800. BHO is the creation of the Institute of Historical Research, School of Advanced Study, University of London, and is used by students, researchers and teachers, worldwide.
To help researchers at this time, all BHO premium content is currently freely available for individual users until 30 September 2020.
BHO editors are also inviting responses to our 2020 Survey: tell us what you like, and don’t like about British History Online, and what you’d like to added to the service.

Jonathan Blaney is Head of Digital Projects and Editor of British History Online.