This post originally appeared on the Digging into Linked Parliamentary Data project blog, and is a guest post by team member Kaspar Beelen.
Problem.
Notwithstanding the recent optimization of Optical Character Recognition (OCR) techniques, the conversion from image to machine-readable text remains, more often than not, a problematic endeavor. The results are rarely perfect. The reasons for the defects are multiple and range from errors in the original prints, to more systemic issues such as the quality of the scan, the selected font or typographic variation within the same document. When we converted the scans of the historical Canadian parliamentary proceedings, especially the latter cause turned out to be problematic. Typographically speaking, the parliamentary proceedings are richly adorned with transitions between different font types and styles. These switches are not simply due to the esthetic preferences of the editors, but are intended facilitate reading by indicating the structure of the text. Structural elements of the proceedings such as topic titles, the names of the MPs taking the floor, audience reactions and other crucial items, are distinguished from common speech by the use of bold or cursive type, small capital or even a combination.
Moreover, if the scans are not optimized for OCR conversion, the quality of the data decreases dramatically as a result of typographic variation. In the case of the Belgian parliamentary proceedings, a huge effort was undertaken to make historical proceedings publicly available in PDF format. The scans were optimized for readability, but seemingly not for OCR processing, and unsurprisingly the conversion yielded to a flawed and unreliable output. Although one might complain about this, it is at the same time highly unlikely that, considering the costs of scanning more than 100.000 pages, the process will be redone in the near future, so we have no option but to work with the data that is available.
Because of the aforementioned reason, names, printed in bold (Belgium) or small capital (Canada), ended up misrecognized in an almost random manner, i.e. there was no logic in the way the software converted the name. Although it showcases the inventiveness of the OCR system, it makes linking names to an external database almost impossible. Below you see a small selection of the various ways ABBYY, the software package we are currently working with, screwed up the name of the Belgian progressive liberal “Houzeau the Lehaie”:
Table 1: Different outputs for “Houzeau the Lehaie”
| Houzeau de Lehnie. | Ilonzenu dc Lehnlc. | lionceau de Lehale. |
| Ilonseau de Lehaie. | Ilonzenu 4e Lehaie. | HouKemi de Lehnlc. |
| lionceau de Lehaie. | Honaeaa 4e Lehaie. | Hoaieau de Lehnle. |
| Ilonzenn de Lehaie. | Heaieaa ée Lehaie. | Homean de Lehaie. |
| Heazeaa «le Lehaie. | Houzcait de Lekale. | Houteau de Lehaie. |
| Hoiizcan de Lchnle. | Henxean dc Lehaie. | Houxcau de Lehaie. |
| Hensean die Lehaie. | IleuzeAit «Je Lehnie. | Houzeau de Jlehuie. |
| Ileaieaa «Je Lehaie. | Honzean dc Lehaie | Houzeau de Lehaic. |
| Hoiizcnu de Lehaie. | Honzeau de Lehaie. | Ilouzeati de Lehaie. |
| Houxean de Lehaie. | Hanseau de Lehaie. | Etc. |
Although the quality of the scanned Canadian Hansards is significantly better, the same phenomenon occurs.
Table 2: Sample of errors spotted in the conversion Canadian Hansards (1919)
| BALLANTYNE | ARCHAMBAULT |
| BAILLANiTYNE | ARCBAMBAULT |
| BALLAINTYNE | ARCHAMBATJLT |
| BALLANT1NE | AECBAMBAULT |
| BALLAiNTYNE | ABCHAMBAULT |
| iBALiLANTYNE | AROHASMBAULT |
| BAIiLANTYNE | ARlQHAMBAULT |
| BALLANTYINE | AECBAMBAULT |
In many other cases even an expert would have hard time figuring out to whom the name should refer to.
Table 3: Misrecognition of names
| ,%nsaaeh-l»al*saai. |
| aandcrklndcrc. |
| fiillleaiix. |
| IYanoerklnaere. |
| I* nréeldcn*. |
| Ilellcpuitc. |
| Thlcapaat. |
These observation are rather troubling, especially with respect to the construction linked corpora: even if, let’s say, 99% of the text is correctly converted, the other 1% will contain many of the most crucial entities, needed for marking up the structure and linking the proceedings to other sources of information. To correct the tiny but highly important 1%, I will focus in this blog post on how to automatically normalize speaker entities, those parts of proceedings that indicate who is taking the floor. In order to retrieve context information about the MPs, such as party and constituency, we have to link the proceedings our biographic databases. Linking will only be possible of the speaker entities in the proceedings match those in our external corpus.
In most occasions speaker entities include a title and a name followed by optional elements indicating the function and/or the constituency of the orator. The semicolon forms the border between the speaker entity and the actual speech. In a more formal notation, a speaker entity consists of the following pattern:
Mr. {Initials} Name{, Function} {(Constituency)}: Speech.
Using regular expression we can easily extract these entities. The result of this extraction is summarized by the figures below, which show the frequency with which the different speaker entities occur.
Figure 1: Distribution of extracted speaker entities (Canada, 1919)

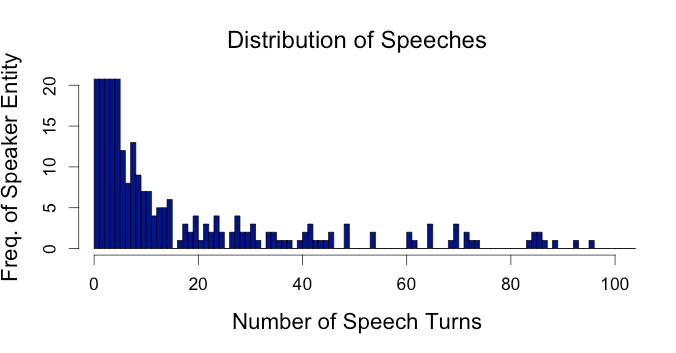
Figure 2: Distribution of extracted speaker entities (Belgium, 1893)
The figures lay bare the scope of the problem caused by these random OCR errors in more detail. Ideally there shouldn’t be more speaker entities than there are MPs in the House, which is clearly not the case. As you can see for the Belgian proceedings from the year 1893, the set of items occurring once or twice alone contains around 3000 unique elements. The output for the Canadian Hansards from 1919, looks slightly better, but there are still around 1000 almost unique items. Also, as is clear from the plots, the distribution of the speakers is more right skewed, due to the large amount of unique and wrongly recognized names in the original scans. We will try to reduce the right-skewedness by replacing the almost unique elements with more common items.
Solution.
In a first step we set out to replace these names with similar items that occur more frequent. Replacement happens in two consecutive rounds: First by searching in the local context of the sitting, and secondly by looking for a likely candidate in the set of items extracted from all the sittings of a particular year. To measure whether two names resemble each other, we calculated cosine similarity, based on n-grams of characters, with n running from one to four.
More formally, the correction starts with the following procedure:
 As shown in table 4, running this loop yields many replacement rules. Not all of them are correct so we need manually filter out and discard any illegitimate rules that this procedure has generated.
As shown in table 4, running this loop yields many replacement rules. Not all of them are correct so we need manually filter out and discard any illegitimate rules that this procedure has generated.
Table 4: Selection of rules generated by above procedure
| Legitimate rules | Illegitimate rules |
| EOWELL->ROWELL | W.HIDDEN -> DENIS |
| McOOIG->McCOIG | SCOTT -> CAEVELL |
| ROWELiL->ROWELL | THOMAS VIEN -> THOMAS WHITE |
| RUCHARBSON->RICHARDSON | BRAKE -> SPEAKER |
| (MdMASTER->McMASTER | CLARKE -> CLARK |
| ABCHAMBAULT->ARCHAMBAULT | |
| AROHASMBAULT->ARCHAMBAULT | |
| CQCKSHUTT->COCKSHUTT |
Just applying these corrected replacement rules, would increase the quality of the text material a lot. But, as stated before, similarity won’t suffice when quality is awful, such as is the case for the examples shown in table 2. We need to go beyond similarity, but how?
The solution I propose is to use the replacement rules to train a classifier and consequently apply the classifier to instances that couldn’t be assigned to a correction during the previous steps. OCR correction thus becomes a multiclass classification task, in which each generated rule is used as a training instance. The right-hand side of the rule represents the class or the target variable. The left-hand side is converted to input variables or features. After training, the classifier will predict a correction, given a misrecognized name as input. For our experiment we used Multinomial Naïve Bayes, trained with n-grams of characters as features, with n againg ranging from 1 to 4. This worked surprisingly well: 90% of the rules it created were correct. Only around 10% of the rules generated by the classifier were either wrong or didn’t allow us to make a decision. Table 4 shows a small fragment of the rules produced by the classifier.
Table 5: Sample of classifier output given input name
| Input name | Classifier output |
| ,%nsaaeh-l»al*saai. | Anspach-Puissant. |
| aandcrklndcrc. | Vanderkindere. |
| fiillleaiix. | Gillieaux. |
| IYanoerklnaere. | Vanderkindere. |
| I* nréeldcn*. | le président. |
| Ilellcpuitc. | Helleputte. |
| Thlcapaat. | Thienpont. |
Conclusion.
As you can see in table 5, the predicted corrections aren’t necessarily very similar to the input name. If just a few elements are stable, the classifier can pick up the signal even when there is a lot of noise. Because OCR software mostly recognizes at a handful characters consistently, this method seems to perform well.
To summarize: What are the strong points of this system? First of all, it is fairly simple, reasonably time-efficient and works even when the quality of the original data is very bad. Manual filtering can be done quickly: for each year of data, it takes an hour or two to correct the rules generated by each of the two processes and replace the names. Secondly: Once a classifier is trained, it can also predict corrections for the other years of the same parliamentary session. Lastly, as mentioned before, the classifier can correctly predict replacements just on the basis of a few shared characters.
Some weak points need to be addressed as well. The system still needs supervision. But, nonetheless, this is worth the effort, because it can enhance the quality of the data significantly, especially with respect to linking the speeches in a later stage. In some cases, however, it can be impossible to assess whether a replacement rule should be kept or not. Another crucial problem is that the manual supervision needs to be done by experts who are familiar both with the historical period of the text and with the OCR errors. That is, the expert has to know which names are legal and also has to be proficient in reading OCR errors.
At the moment, we are trying to improve and expand the method. So far, the model uses only the frequency of n-grams, and not their location in a token. By taking location into account, we expect that we could improve the results, but that would also increase dimensionality. Besides adding new features, we should also experiment with other algorithms, such as support-vector machines, which perform better in a high-dimensional space. We will also test whether we can expand the method to correct other structural elements of the parliamentary proceedings, such as topical titles.